基于赛前多维数据分析的CBA比赛胜负预测研究方法模型构建与应用
本文围绕基于赛前多维数据分析的CBA比赛胜负预测研究方法模型的构建与应用展开讨论。随着体育赛事的竞争日益激烈,数据分析在竞技体育中的应用已成为提升球队战术水平和预测比赛结果的重要工具。尤其是在CBA(中国篮球协会)比赛中,赛前通过对球员、球队、历史对阵、场地等多维数据的综合分析,可以为比赛结果的预测提供更加准确的依据。本文将从四个方面对这一研究方法模型进行详细阐述,首先介绍数据分析的基本框架与方法,其次探讨如何构建有效的预测模型,第三部分分析预测模型在CBA比赛中的应用场景,最后讨论数据分析在实际操作中面临的挑战与解决方案。通过对这些内容的探讨,本文力图为基于多维数据分析的CBA比赛胜负预测提供理论支持与实践指导。
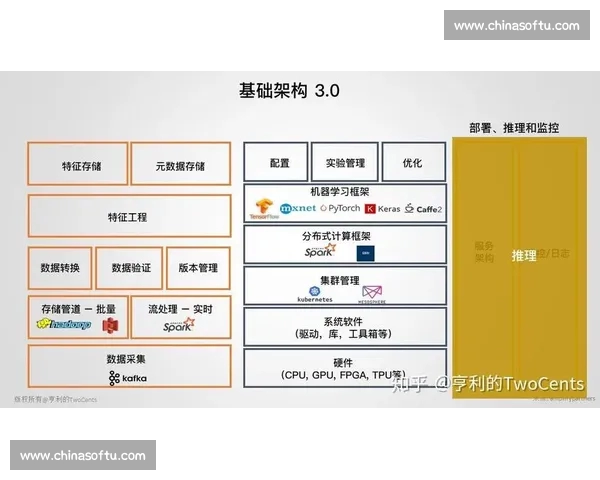
1、赛前多维数据分析的基本框架
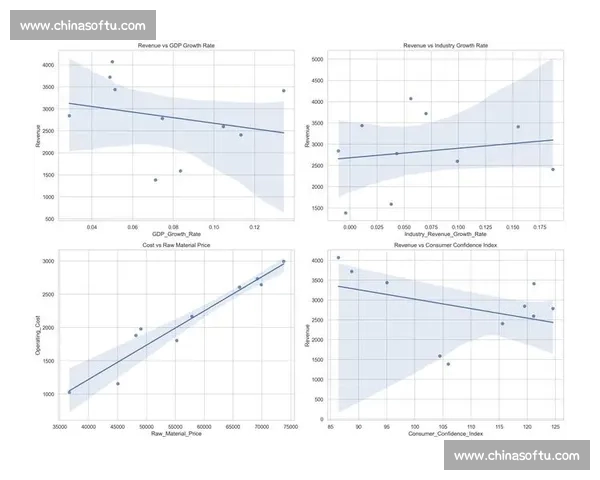
赛前多维数据分析是基于对大量历史比赛数据的收集与整理,运用统计学、机器学习等方法对比赛各个可能影响因素进行深入分析的过程。在CBA比赛中,数据分析的维度通常包括球员个人表现、球队整体战术、历史对战记录、赛季数据、场地环境等。为了能够对比赛结果做出准确的预测,首先需要定义一个清晰的数据框架,并通过数据清洗与特征工程来提升数据的质量。
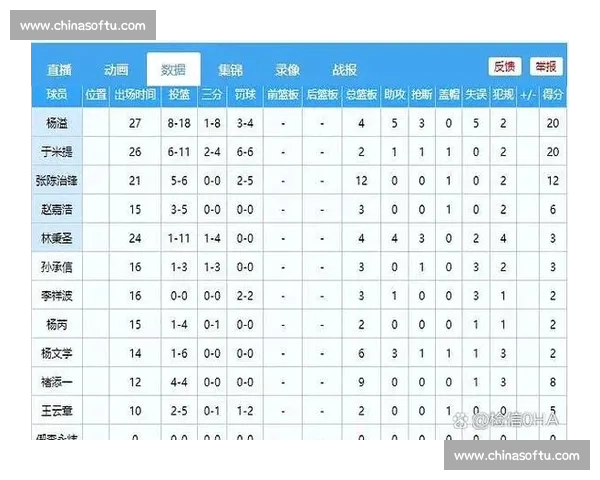
首先,球员的个人数据是分析的核心之一。每位球员的得分、助攻、篮板等基础数据,以及他们在不同比赛中的表现波动性、伤病记录、体能状态等,都是影响比赛胜负的关键因素。数据分析的第一步就是收集并整理这些个体数据,分析出球员的强弱项,从而为球队的整体表现预测提供参考依据。

其次,球队的整体数据也是不可忽视的一部分。球队的战术体系、进攻与防守效率、平均得分、失分、篮板等统计数据,往往直接影响比赛的走势。分析球队在不同类型比赛中的表现,比如主客场比赛、强弱对阵等,可以帮助预测比赛的胜负趋势。在此基础上,结合球队的赛季表现和战术调整,就能进一步完善赛前分析模型。
2、构建CBA比赛胜负预测模型
在赛前多维数据分析的基础上,构建CBA比赛的胜负预测模型需要运用合适的算法和技术手段。机器学习算法是目前最常见且最有效的模型构建方式,常用的算法有决策树、支持向量机、神经网络等。这些算法可以通过对历史比赛数据的学习,找到不同数据特征之间的关联,从而预测比赛结果。
决策树是一种易于理解且应用广泛的分类模型。通过将多维数据作为输入,决策树可以基于特征的不同取值进行逐步分割,最终生成一棵树形结构,从而根据每个比赛的特征值预测比赛结果。决策树的优点是模型透明、易于解释,尤其适合初步的预测分析。
除了决策树,支持向量机(SVM)也是一种常见的分类算法,它通过在高维空间中寻找最优超平面,能够处理更为复杂的数据关系。对于CBA比赛的预测,SVM可以在大量非线性特征数据中找到潜在的规律,有助于提高预测的准确性。同时,神经网络技术也开始在体育数据分析中得到广泛应用,尤其是在处理复杂的非线性关系时,神经网络能够通过多层次的网络结构不断优化预测结果。
3、预测模型在CBA比赛中的应用
基于赛前多维数据分析的胜负预测模型,在CBA比赛中的应用主要体现在以下几个方面。首先,预测模型可以帮助教练组和分析师在赛前制定更加科学的战术方案。通过对对手的多维数据分析,教练组可以了解对方的强项和弱点,进而有针对性地布置防守策略或进攻手段。
其次,预测模型能够辅助球员的状态评估与调整。通过对球员历史表现和体能状态的分析,预测模型可以为球员提供更为精准的状态预估,帮助他们在比赛前调整个人训练计划,提升比赛中的表现。同时,针对球员的伤病记录,预测模型还能为球员的出场时间和恢复周期提供数据支持。
此外,预测模型还可以在比赛后期为媒体和观众提供实时分析。通过结合赛前预测和比赛中的实时数据,预测模型可以实时更新胜负预测的准确性。这不仅为球迷提供了更丰富的观赛体验,也为媒体报道提供了更加有力的数据支持。
4、数据分析面临的挑战与解决方案
虽然基于多维数据的CBA比赛胜负预测模型具有很高的应用价值,但在实际操作过程中,仍然面临一些挑战。首先,数据的质量与完整性是影响模型预测准确度的关键因素。由于部分比赛数据可能存在遗漏或不准确,如何保证数据的完整性和准确性,成为模型建设的首要问题。为此,数据收集时需要从多个来源获取,并通过清洗、去重等手段进行处理。
米兰,米兰·(milan)中国官网-球迷群英汇聚,米兰mila官网,米兰·(milan),米兰官网首页登录入口,米兰(milan)体育-米兰官方网站,米兰·(milan)中国官方网站米兰·(milan),米兰官网首页登录入口其次,数据分析的复杂性也给模型构建带来了挑战。CBA比赛中,影响比赛胜负的因素众多,且这些因素之间存在复杂的非线性关系。在这种情况下,单纯依靠传统的统计方法可能难以取得理想的预测效果。因此,深度学习等更为复杂的算法应运而生,它可以在大量的训练数据中挖掘潜在规律,提升模型的预测精度。
最后,数据分析模型的实时更新和调试也是一大难题。CBA联赛的赛季非常长,球员的状态和球队战术会随着时间变化而发生动态变化。如何及时更新模型,使其适应不断变化的数据环境,是提升预测准确度的关键。因此,需要在模型中引入实时数据监测和调整机制,以应对赛季中的各种不确定因素。
总结:
基于赛前多维数据分析的CBA比赛胜负预测研究方法模型,是体育数据分析领域的重要研究方向。通过收集和分析球员、球队、历史对战、赛季数据等多维信息,能够有效地预测比赛的胜负趋势,为教练组、球员以及媒体提供决策支持。然而,数据的质量、分析的复杂性以及模型的实时更新等问题仍然是当前研究中的重要挑战,需要通过技术手段不断优化解决。
未来,随着数据分析技术的不断发展,CBA比赛胜负预测模型将会变得更加精确和智能。通过不断完善模型框架,引入更先进的机器学习和人工智能技术,预测准确度将进一步提高,推动体育数据分析在实际应用中的广泛普及。这不仅能提升球队的竞技水平,也将为球迷带来更具互动性和娱乐性的观赛体验。